
参与本文的机器人有

轻轻的,视觉中国又上线了。
今天不提商业,只说技术。
摄影师们有视觉中国“保价护航”,那字体设计师们呢!嗯,有方正,有汉仪。
那独立字体设计师们呢?
...
今天,就让我们来做个字体界的视觉中国吧!
准备工作
假设我们发现一张图,里面可能用到了我们设计的一款字体,我们要通过算法把它识别出来。
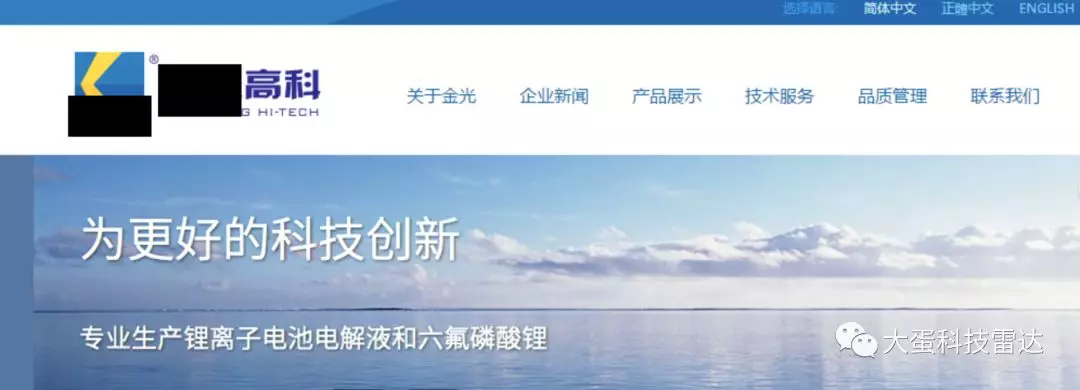
上面是某家公司的首页,里面的高科的高字用到了汉仪出品的一款很流行的菱心体。

我们的准备工作包括
- 找到目标图片(网页截图,海报啥的都行)
- 目标字体(菱心体)的字体文件(.TTF)文件
流程分解
经过简单调研,我们发现,“检测图中是否有F字体”这件事,可以分解成下面相对独立的几个过程
- 定位(Localization):从图中找出所有汉字的位置区域
- 识字(OCR):对上面找到的每个区域进行印刷体识别,识别出其中的每个字
- 判断(Classifier):检查识别出的每个字,如果是一个高频字C,则将该字传入"F体C字识别器",得到结果
很抽象是吧!下面的漫画解释的更清楚。
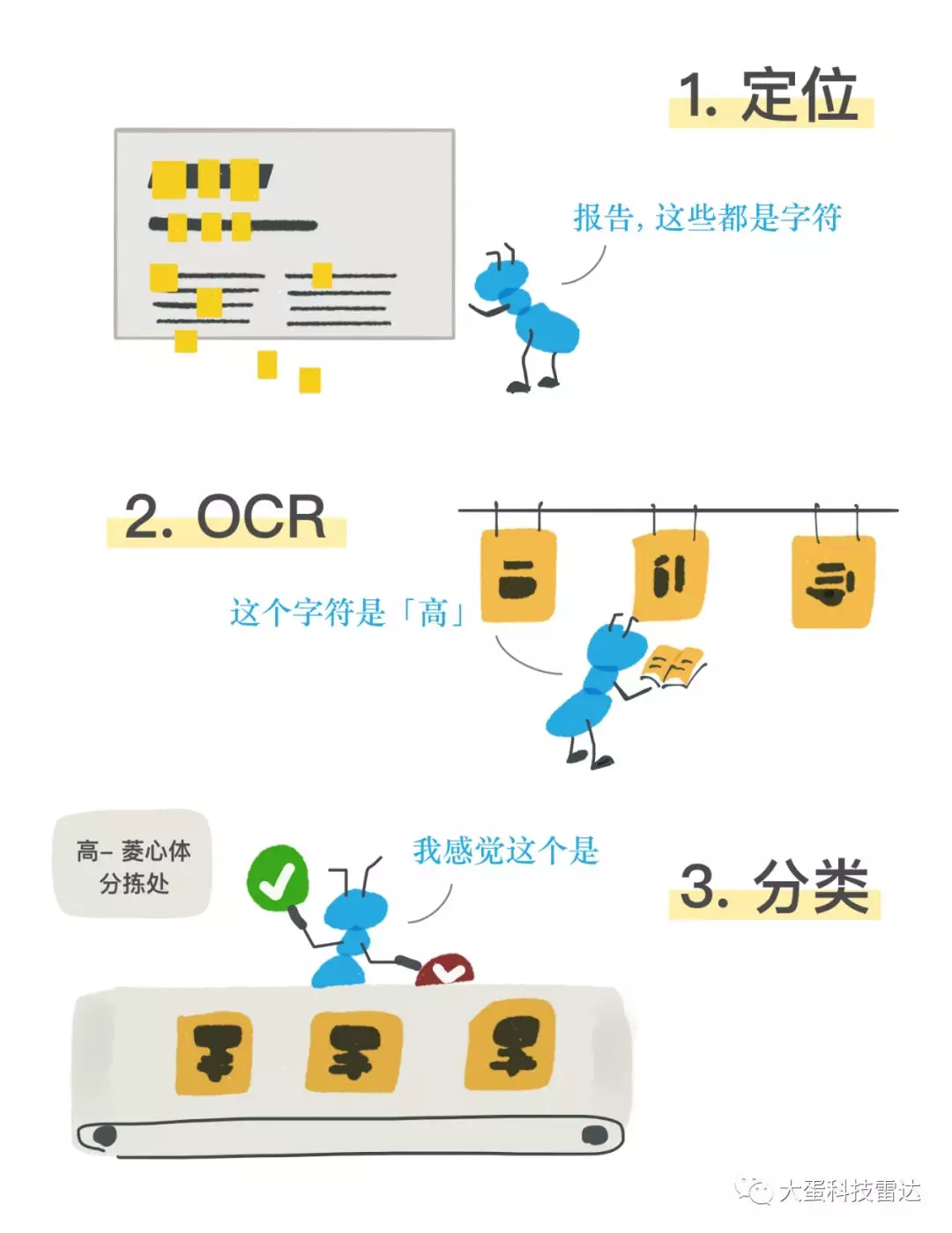
(DailyBeat断更后,改行事漫画的超龙出品)
其中前两个阶段都是与字体无关的通用文字识别/定位问题,业界已有丰富的商用或开源解决方案,我们直接使用他们的结果,不再重复造轮子了。
真正需要自己实现的,是“给定字体F和汉字C,判别一幅图中是否有F体的C字”。后面将会看到,这个流程会使模型的设计和训练变得单纯而简单。
===
前方高能
请叫醒你99%的脑细胞🧠
===
模型训练
识别任何一种特征都需要一个模型,字体本身就是一种模型(听说现在的可变字体可复杂了)。
前面说到,我们要训练的是一堆“F字体C字识别器”,也就是说我们要构造出一堆“F字体C字识别模型”。
下文中我们定义
F = “汉仪菱心体”
C = “高”
也就是,我们要构建一个“汉仪菱心体的高字识别器”。它接受一张正方形的RGB图像,返回“输入图像是一个汉仪菱心体'高'字”的概率。

这是一个典型的图像识别问题,如今主流且易用的解决方法是使用卷积神经网络(CNN)进行二分类。
卷积神经网络能够有效地从图像中抽取特征:从边缘、形状等简单而局部的特征,到逐层组合而成的高层语意特征。得到高层特征之后,利用多层神经元进行编码,实现分类。
具体到本问题,由于前面有OCR识别的结果,我们假定它的准确率很高。进入模型的数据大概率是不同字体的”高“字,CNN只要学出菱心体的‘高'与其他字体的”高“的不同特征即可。根据经验,这个网络不应该太复杂,我们使用了一个短小简单的网络,定义如下:
- 输入32*32 8bit灰度图
- 32个 5*5卷积
- 2*2 最大池化
- 64个 5*5卷积
- 2*2 最大池化
- 全连接到512个ReLU神经元
- 再次全连接到512个ReLU神经元
- 二输出的softmax(为日后扩展方便使用了softmax,二分类下使用逻辑回归更简单)
(此处应有专业的神经网络结构图,可是超龙说前面的漫画已经耗尽数十年功力=.=)
这个网络类似早期CNN LeNet-5,它参数较少,训练容易,在比较简单的文字分类问题上够用了。
确定网络结构的同时,我们构造了一批训练样本。我们选取了10+个常见的非菱心字体,作为负样本,每字体构造500张“高”字图。另外构造5000个菱心体的高字图。
(负样本最好不要选取特征和菱心体太相近的)
按照视觉中国的套路,待识别的图片主要来自网站截图、手机截图的OCR结果。在这样的场景下,模型需要忽略这些噪音:
- 字缩放: OCR给出的矩形框可能稍大或稍小(用过百度OCR的同学应该有共鸣)
- 小位移:OCR给出的矩形框可能稍偏
- 旋转:海报图可能将字倾斜使用(顶多十几度,再大了就当看不见吧)
- 绝对灰度:前景深、背景浅或反过来,都应当不影响结果
- 由于图片缩放、压缩等造成的模糊
于是,在构造正负训练样本时,我们随机生成了带有上述噪音的数据,下面是几个样例。

将这样的样本输入模型,并进行训练,在我们使用的带Nvidia GTX 1080T显卡的工作站上,训练一次仅需要几分钟的时间。
模型验证
训练完成之后,我们准备了训练/测试期间,模型从未见过的样本作为验证集,正负各10张。
模型预测结果(数据)
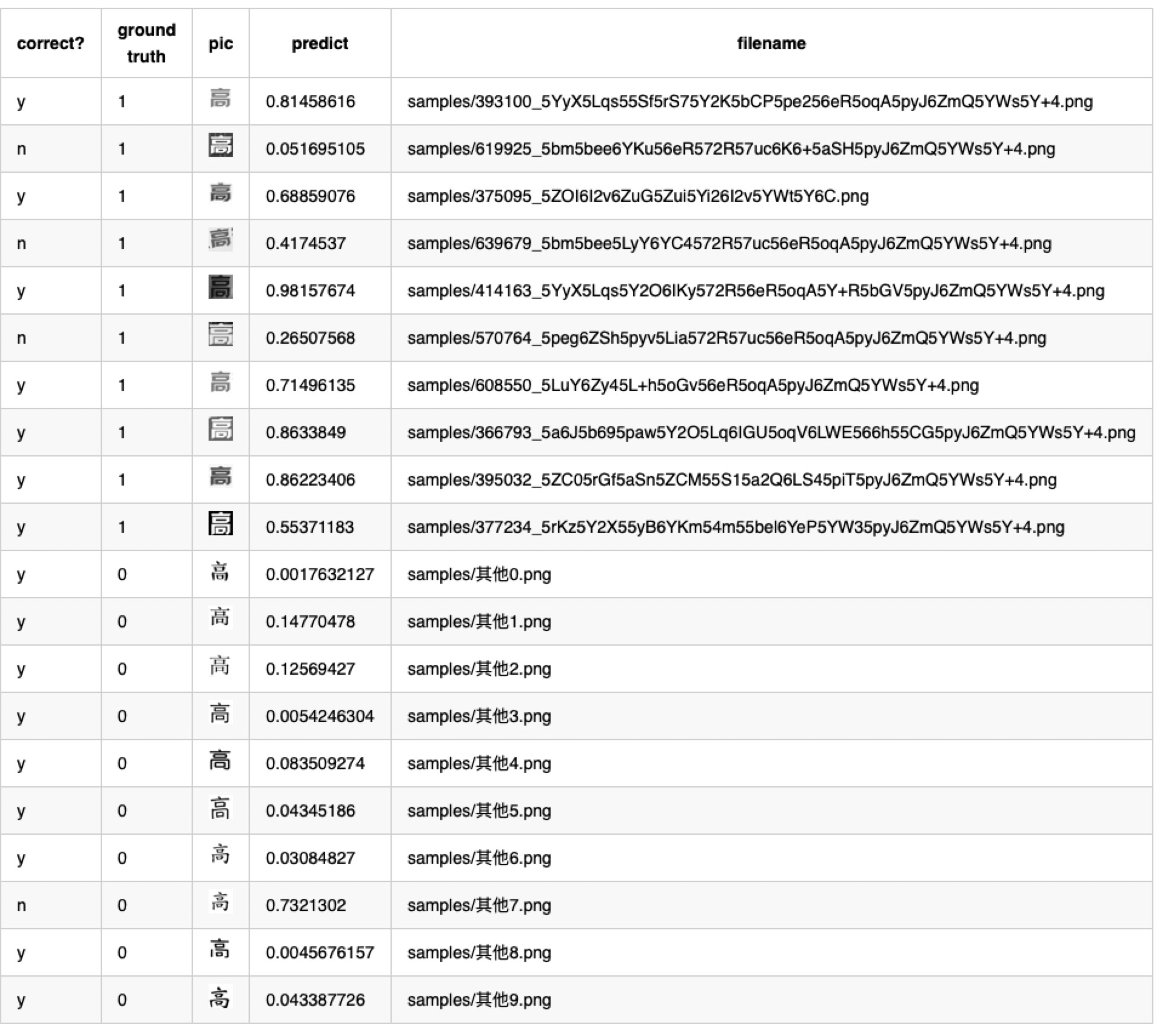
混淆矩阵如下

- 精准率 precision = 7/8 = 87.5%
- 召回率 recall = 7/10 = 70%
模型预测结果(解释)
一个AI识别算法的衡量标准最核心的两个指标:精准率(Precision),召回率(Recall)。
精准率是说:我说他是这菱心体的,他真的是菱心体的概率。当然是越高越好。
召回率指的是:真的是菱心体的,有多大概率会被我挑出来。当然也是越高越好。
上面的小模型的结论是:精准率87.5%,召回率70%。
这个场景下,精准率比召回率更重要。因为精准率越高,我们需要人工验证的就更少。至于我们没抓出来的“漏网之鱼”,就留待日后我们不断提升的算法来捕获啦。
至此,我们用一个很小的验证集,验证了使用简单CNN来进行字体识别的技术可行性。
以上就是我们历时数十万(秒),耗资千万(脑细胞)为大家调制出来的一碗入门级的字体中国蘑菇汤,希望大家品尝愉快🥣。

如果对我们感兴趣,或者想洽谈合作,请在公众号留言,添加下面这位机器人先生,或者发邮件给mr.robot@bigeggai.com

关注大蛋科技雷达,获得更多有意思的AI项目。
大蛋科技是一家提供技术咨询、设计、开发服务的初创企业。

Comments